


Arquivo para a ‘Mineração de dados’ Categoria
Pesquisa desenvolve novo teste de Turing
27
nov
 Alan Turing um pioneiro da Computação, que desenvolveu um modelo teórico chamado depois de Máquina de Turing, completado depois pelo matemático Alonzo Church em 1938, que deram origem a todos algoritmos de computação, o princípio básico estabelecia:
Alan Turing um pioneiro da Computação, que desenvolveu um modelo teórico chamado depois de Máquina de Turing, completado depois pelo matemático Alonzo Church em 1938, que deram origem a todos algoritmos de computação, o princípio básico estabelecia:
“O algoritmo consiste de um conjunto finito de instruções simples e precisas, que são descritas com um número finito de símbolos”.
Sobre esta ideia foi proposto um teste, chamado de Teste de Turing, que se algo fosse proposto a uma pessoa e uma máquina e não pudessemos decidir qual resposta era a de uma máquina, teria atingido uma “inteligência” de máquina.
Agora um professor da Georgia Tech, Mark Riedi afirmou ter desenvolvido um algoritmo que ele descrever como uma forma mais rigorosa de avaliar o potencial inteligente de uma máquina do que o famoso teste de Turing, conforme noticia o site da Georgia Tech.
Os novos testes de Riedi, chamado de Teste de Criatividade de Inteligencia Artificial e o Lovelace 2.0, são baseados no teste de Lovelace, criado em 2001, testando a produção de uma obra de arte ou outro trabalho humano bastante criativo.
Riedl acredita que o teste original era muito subjetivo e criou parâmetros específicos para o seu teste que devem ser seguidos por um avaliador humano.
Riedl estará apresentando seu novo teste com o trabalho Beyond the Turing Test, no Workshop da Association for the Advancement of Artificial Intelligence (AAAI) em janeiro de 2015, em Austin, Texas.
Redes Sociais investigam “consenso”
10
set
É claro que redes sociais em geral desenvolvem dissensos, a maioria das opiniões particulares nem sempre devem convergir para um consenso ou mesmo uma “crença”, quando fatores subjetivos estão influenciando determinada posição para a qual um “cluster” (grupo) da rede está tendendo.
devem convergir para um consenso ou mesmo uma “crença”, quando fatores subjetivos estão influenciando determinada posição para a qual um “cluster” (grupo) da rede está tendendo.
Um modelo computacional foi desenvolvido para estudar um modelo no qual um agente inteligente poderá indicar a tendência para algum consenso ou “crença” em redes sociais, o estudo foi desenvolvimento pela Universidade de Miami, conforme notícia do site da universidade.
O diretor do projeto professor U.M. Kamal Premaratne, afirmou que “o novo modelo nos ajuda a entender o comportamento coletivo de agentes adaptativos, sejam eles: pessoas, sensores, bancos de dados ou entidades abstratas – através de padrões de comunicação que são característicos em redes sociais”.
Os dados consultados pelo modelo incluem aquilo que podem modelar opiniões, e como estão opiniões vão sendo atualizadas, e quando podem chegar a um consenso, e assim o modelo tem também a capacidade de verificare incertezadas ligados a dados leves quando combinados a dados concretos, e assim o professor destacou “nosso estudo leva em conta as dificuldades associadas com a natureza não estruturada da rede”, que é o que não se compreende quanto a dinâmica da rede, esta dinâmica não significa que não possa caminhar em direção a uma consenso ou uma forma de crença.
Assim “ao usar um novo” mecanismo de atualização de crença, “nosso trabalho estabelece as condições em que os agentes podem chegar a um consenso, mesmo na presença destas dificuldades.” e o professor Premaratne afirma que a nova pesquisa tem consenso compatível com uma estimativa confiável da verdade terrestre e este reforça a credibilidade de um agente inteligente, e a opinião consensual fica mais perto de opinião do agente.
Os dados completos da pesquisa estão no número de agosto da revista do IEEE Journal of Selected Topics in Signal Processing.
Computação em ultra-escala é estudada
09
set
Os sistemas de computação paralela e distribuída chamado UltraScale está sendo estudado por cerca de duas centenas de mais de 40 países visando construir uma infraestrutura para a próxima geração de computadores, conforme portal da Universidade Carlos III de Madri, ES.
de duas centenas de mais de 40 países visando construir uma infraestrutura para a próxima geração de computadores, conforme portal da Universidade Carlos III de Madri, ES.
Muitas são as tarefas que podem precisar deste tipo de serviço e este modelo de computação permite que muitas tarefas são executadas ao mesmo tempo, de forma coordenada para resolver um problema, com base no princípio de que um grande problema podem ser dividido em diversos menores e são executados simultaneamente.
Mas há também um morela que usa tanto computação em gride como em nuvem, usa um grande número de computadores organizados em grupos em uma infra-estrutura distribuída, e este poderá executar milhões de tarefas ao mesmo tempo geralmente trabalhando em problemas independentes e em problemas típicos de big data.
O sistema chamado Nesus, tem como objetivo científico estudar os desafios apresentados pela próxima geração de sistemas de computação que serão tanto caracterizados por seu grande tamanho quanto pela complexidade, e como estes são desafios significativos, deverá haver um plano tanto sua construção como para sua exploração e utilização.
O Departamento de Computação da Universidade Carlos III da Espanha, que é coordenadora do projeto, afirmou pelo professor titular Jesús Carretero: “Nós tentamos analisar todos os desafios existem e ver como eles podem ser estudados de forma holística e integrados, para ser capaz de fornecer um sistema mais sustentável”.
Bigdata extremo: tomada de posição
08
abr
Análise das situações de dados em todo mundo, e em especial no Brasil, revelam a fragilidade da segurança  dos dados em todo mundo, e a facilidade de extrair dados na ‘deep web’.
dos dados em todo mundo, e a facilidade de extrair dados na ‘deep web’.
Mas os alarmistas e especuladores raramente apontam caminhos para resolver este problema, primeiro é claro, com normas que estimulem o uso de ferramentas para explorar dados complexos na Web, o chamado Big data, e depois com medidas de segurança que protejam os dados privativos e que também pode ser usado para dados científicos.
O professor Volker Markl da Universidade Técnica de Berlim desenvolveu em na recente Oficina de Big Data o método em que explorou os desafios das grandes análise de dados atual, através do uso de um software chamado Stratosphere, conforme a HPC-wire, que tem o código open-source em licença Apache 2.0.
Stratosphere integra as vantagens do tradicional método do MapReduce / Hadoop, com algumas abstrações de programação em Java e Scala em tempo de execução de alto desempenho para facilitar análise de dados in-situ, de dados massivamente paralelos.
Software que ajuda mineração científica
30
nov
 Jaron Lanier se perguntava sobre a consciência e sobre as possibilidades linguísticas da computação, como é músico pensava na música, mas como pesquisador podemos pensar nas possibilidades de ajuda às pesquisas científicas, como foi feito no Baylor College of Medicine em colaboração com a IBM.
Jaron Lanier se perguntava sobre a consciência e sobre as possibilidades linguísticas da computação, como é músico pensava na música, mas como pesquisador podemos pensar nas possibilidades de ajuda às pesquisas científicas, como foi feito no Baylor College of Medicine em colaboração com a IBM.
Conforme um relato no site do MIT Technology Review, um software que lê mais de 60 mil trabalhos, pode auxiliar nas descobertas cruzando dados destes trabalhos.
O software analisa frases nos documentos, e poderia construir uma nova compreensão do são as enzimas conhecidas quinases, importantes para o tratamento do câncer.
Ao analisar esta enzima, o software ele gerou uma lista de outras proteínas que embora a literatura mencione, provavelmente não são descobertas quinases, mas com base no que ele já se sabia poderam ser identificados.
O software foi apresentado no IBM Almanden Colloquium: the cognitive enterprise, no dia 19 de novembro passado.
A maioria de suas previsões testadas até agora resultaram corretas, segundo os pesquisadores, normalmente os gastos em pesquisas podem chegar a $ 500.000.000 e US $ 1 bilhão de dólares para desenvolver uma nova droga, e 90 por cento das drogas testadas nunca irão ao mercado, diz Ying Chen, pesquisador da IBM.
Web 3.0: cunhar palavras e dar-lhes sentido
22
nov
Não é da Web só que estou falando, mas também e principalmente de pessoas, dar sentido, em especial humano, às coisas a nossa volta requer reflexão e agimos mais e mais apenas por impulso.
a nossa volta requer reflexão e agimos mais e mais apenas por impulso.
Por isto falei no blog anterior da palavra Selfie, mas já falei do Instagram e das pessoas comuns e paisagens cotidianas que passam por nosso dia a dia “fotográfico”, assim também é o caso da Web 3.0, moda ou tendência ?
Foi John Markoff que cunhou a palavra Web 3.0, no New York Times, a Web 2.0 já acontecia, ela criou centenas ou milhares de aplicativos (se considerarmos os Apps dos celulares) e incluiu o usuário como produtor comum de informação, agora fotos, postagens, comentários e “hashtags” estão aí chamando nossa atenção, mas estas pessoas SEMPRE deveriam ser vistas e ouvidas, não eram.
O problema do nosso dia a dia, e também da Web que é um reflexo e não uma idealização do dia-a-dia como pensam alguns, é que a muita coisa que “carece” de sentido, e descobrimos ao olhar milhares de fotos, de palavras e de vídeos que precisamos significa-las ou ressignificá-las.
John Markoff sugeriu questões simples, tais como: “Estou à procura de um local quente para passar as férias e disponho de US$ 3 mil. Ah, e tenho um filho de 11 anos”, mas na verdade pensava em negócios, como o próprio titulo e artigo sugerem, dando o exemplo empresa de Spivak, a Radar Networks, que trabalha na exploração do conteúdo de sites de computação social, que permitem aos usuários colaborarem na reunião e adição de seus pensamentos a uma grande quantidade de conteúdos, de viagem a filmes.
Mas a Web 3.0 parece agora estar encontrando seu caminho, projetos como DBpedia e VIAF (Virtual International Authorit File) estão indicando um caminho mais técnico que social, embora possa contribuir a isto, ainda há uma caminho nesta “construção”.
A vantagem de ser visível
15
out
O Facebook decidiu desabilitar um recurso de privacidade que permitia aos usuários limitarem quem podia encontrar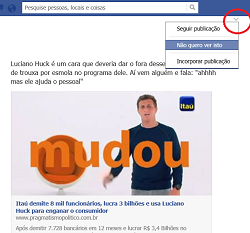 seus perfis pelas buscas dentro da rede social, ao mesmo tempo em que anuncia uma ferramenta de busca concorrente ao Google (veja nota no Globo), portanto a questão é a visibilidade, ao contrário do bom filme “A vantagem de ser invisível” que discute os adolescentes de hoje.
seus perfis pelas buscas dentro da rede social, ao mesmo tempo em que anuncia uma ferramenta de busca concorrente ao Google (veja nota no Globo), portanto a questão é a visibilidade, ao contrário do bom filme “A vantagem de ser invisível” que discute os adolescentes de hoje.
No ano passado, muitos internautas já haviam desabilitado, mas ela permitia que usuários a utilizassem para bisbilhotas perfis e relações na rede social sem ficarem conhecidos, é o que fazem muitos órgãos governamentais (veja o post anterior).
O Facebook justificou esta remoção informando que percentual “de apenas um dígito” dos cerca de 1,2 bilhão de membros que usavam o recurso, mas o fato é que este perfil podia ser usado para invasão de privacidade, crimes e “segurança”.
Os usuários podem continuar proteger sua privacidade limitando o público que terá acesso às suas postagens (apenas amigos, certos grupos ou todos os usuários, por exemplo) e também podem evitar postagens indesejadas e emitir sua opinião sobre campanhas negativas que invadiram a rede e tags também indesejadas.
Lembramos os usuários do “face” que pode-se tornar invisível campanhas que denigrem a imagem de alguém, de cunho fundamentalista ou simples bobagens, há uma ferramenta do lado de cada post para tornar estas coisas invisíveis.
Um problema interessante de Big Data
10
out
Simon DeDeo , um investigação em matemática aplicada e sistemas complexos do Instituto Santa Fé, tinha um problema, conforme postado na revista Wired.
tinha um problema, conforme postado na revista Wired.
Ele estava colaborando em um novo projeto para analisar de dados a partir dos arquivos do tribunal Old Bailey de Londres, um tribunal criminal central da Inglaterra e do País de Gales 300 anos “.
Mas não haviam dados limpos (dizemos estruturados) como em um formato de planilha Excel habitual simples, incluindo variáveis como acusação, julgamento e sentença para cada caso, mas sim cerca de 10 milhões de palavras gravadas durante pouco menos de 200 mil julgamentos.
Como se poderia analisar esses dados ? DeDeo pergunta: “Não é o tamanho do conjunto de dados, que era difícil, por padrões de dados grandes , o tamanho era bastante controlável”. Foi esta enorme complexidade e falta de estrutura formal que representava um problema para estes “grandes dados” que o perturbou.
O paradigma da pesquisa envolveu a formação de uma hipótese, decidir precisamente o que se pretendia medir, em seguida, construir um aparelho para fazer essa medição com a maior precisão possível, não é exatamente como física onde você controla variáveis e tem um número limitado de dados.
Alessandro Vespignani, um físico da Universidade de Northeastern, que é especializada em aproveitar o poder das redes sociais para surtos modelo de doença, o comportamento do mercado de ações, as dinâmicas sociais coletivos, e os resultados eleitorais, coletou muitos terabytes de dados de redes sociais como o Twitter, esta abordagem pode ajudar a tratar textos escritos fora das redes sociais.
Cientistas como DeDeo e Vespignani fazem bom uso dessa abordagem fragmentada para a análise de dados grande, mas o matemático da Yale University, Ronald Coifman diz que o que é realmente necessário é o grande volume de dados equivalente a uma revolução newtoniana, comparando com a invenção do cálculo do século 17, que ele acredita que já está em andamento.
Coifman afirma “Temos todas as peças do quebra-cabeça – agora como é que vamos realmente montá-los”, ou seja, ainda temos que avançar para tratar dados dispersos.
Mais sobre o Feedspot
26
set
Além de recursos básicos RSS leitor como a etiquetagem, organização de pastas, atalhos de teclado, lista / expandido vista, 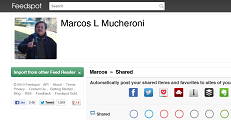 classificação e vários outros, o próprio blog indica três características únicas do recurso:
classificação e vários outros, o próprio blog indica três características únicas do recurso:
Quanto ao social, ele permite seguir outros usuários e ver as mensagens compartilhadas por eles em seu feed de negócios, com links externos, imagens e vídeos. Para isto você pode compartilhar um artigo ou uma nota pessoal com os seus seguidores.
Quanto a pesquisa e aos folders, pode-se procurar em pastas públicas criados por outros usuários e passar a seguir estas pastas, tais como: tecnologia, fofocas de celebridades, comidas, histórias em quadrinhos e muitas outras conforme o interesse. Elas também podem ser compartilhadas.
A terceira característica é um compartilhamento avançado, onde o usuário pode querer compartilha uma ou várias redes sociais, por exemplo, postas seus favoritos diretamente para o Facebook, Twitter, Pocket ou Bufferapp; havendo ainda um feed RSS para suas pastas, tags, favoritos ou itens compartilhados.
Feedspot ressuscitará o RSS ?
25
set
 Em janeiro morria com apenas 26 anos o criador do RSS (veja nosso post) Aaron Swarz, que aos 16 já tinha feito seu maravilhoso Feed, logo depois viriam as notícias de desativação do RSS.
Em janeiro morria com apenas 26 anos o criador do RSS (veja nosso post) Aaron Swarz, que aos 16 já tinha feito seu maravilhoso Feed, logo depois viriam as notícias de desativação do RSS.
Agora é anunciado o Feedspot que tenho a alegria de ser um dos avaliadores, recebendo esta notícia de um dos seus criadores: Anuj que me enviou a mensagem:
“I’d like to invite you to beta test Feedspot”
Prontamente aceitei e pedi a ele um release e ele me enviou um post do seu blog.
Lá eu li com satisfação a missão do novo feed: “Nossa missão é trazer RSS volta para seus primeiros dias de glória. Para isso, estamos repensando o produto Leitor de RSS e construção de uma plataforma completamente nova a partir do zero. RSS nunca chegou aos usuários comuns de internet”. Grande, brilhante … vamos lá.
Então querem transformar o “leitor de RSS em um produto social, integrando a partilha ea funcionalidade social profunda no núcleo do produto. A maneira Tumblr revolucionou a categoria de blogs, adicionando uma camada social, a nossa meta é fazer exatamente a mesma coisa para o leitor de RSS mercado”.
E acrescentou: “O objetivo da Feedspot é aplicar a mesma lógica para o leitor de RSS e ao fazê-lo … apelando para o mainstream”.
A meta parece maravilhosa, vamos verificando e dando mais dicas do Feedspot.
