


Arquivo para a ‘Information Retrieval’ Categoria
Revolutionary method for videos
19
Sep
Researchers at Carnegie Mellon University have developed a method that without human intervention modifies a video content from one style to another. The method is based on a data processing known as Recycle-GAN that can transform large amounts of video making them useful for movies or documentaries.
modifies a video content from one style to another. The method is based on a data processing known as Recycle-GAN that can transform large amounts of video making them useful for movies or documentaries.
The new system can be used for example to color films originally in black and white, some already made like the one shown in the video below, but the techniques were expensive and needed a lot of human effort during working hours.
The process arose from experiences in virtual reality, which in addition to the attempts to create “deep falsities” (altering objects or distorting contents, could appear a person inserted in an image, without it was allowed, in everyday scenes almost always happens this and much people do not accept.
“I think there are a lot of stories to tell,” said Aayush Bansal, a Ph.D. student at the CMU Robotics Institute, who said of a film production that was the main motivation to help design the method, he said, allowing that the films were produced faster and cheaper, and added: “it is a tool for the artist that gives them an initial model that they can improve,” according to the CMU website.
More information on method and videos can be found at Recycle-Gan website.
Basic Questions of Semantic Web and Ontologies
05
Jul
We are always faced with concepts that seem common sense and are not, is the case of many examples: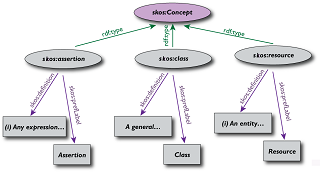 social networks (confused with the media), fractals (numbers still too generic to be used in everyday life, but important), the artificial intelligence, finally innumerable cases, being able to go to the virtual (it is not the unreal), the ontologies, etc.
social networks (confused with the media), fractals (numbers still too generic to be used in everyday life, but important), the artificial intelligence, finally innumerable cases, being able to go to the virtual (it is not the unreal), the ontologies, etc.
These are the cases of Semantic Web and Ontologies, where all simplification leads to an error. Probably so, one of the forerunners of the Semantic Web Tim Hendler, wrote a book Semantic Web for Ontologists modeling (Allemang, Hendler, 2008).
The authors explain in Chapter 3 that when we speak of Semantic Web “of a programming language, we usually refer to the mapping of language syntax to some formalism that expresses the” meaning “of that language.
Now when we speak of ‘semantics’ of natural language, we often refer to something about what it means to understand the utterance – how to go from the structured lyrics or sounds of a language to some kind of meaning behind them.
Perhaps the most primitive part of this notion of semantics is a representation of the connection of a term in a statement to the entity in the world to which the term refers.” (Allemang, Hendler, 2008).
When we talk about things in the world, in the case of the Semantic Web we talk about Resources, as the authors say perhaps this is the most unusual thing for the word resource, and for them a definition language called RDF has been created as a Resource Description Framework, and they on the Web have a basic identification unit called URI, along with a Uniform Resource Identifier.
In the book the authors develop an advanced form of RDF called RDF Plus, which already has many users and developers, to also model ontologies using a language of their own that is OWL, the first application is called SKOS, A Simple Organization of Knowledge, which proposes the organization of concepts such as thesaurus dictionaries, taxonomies and controlled vocabularies in RDF.
Because RDF-Plus is a modeling system that provides considerable support for distributed information and federation of information, it is a model that introduces the use of ontologies in the Semantic Web in a clear and rigorous, though complex, way.
Allemang, D. Hendler, J. Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL, Morgan Kaufmann Publishing, 2008.
News in Google News
02
Jul
After several announcements, finally in the second half of May Google launched its new application, only now I have been able to take a look at the application that replaces Google Play Nwesstad, now with use of Artificial Intelligence.
only now I have been able to take a look at the application that replaces Google Play Nwesstad, now with use of Artificial Intelligence.
The application works on using machine learning to train algorithms that scour complex and recent news stories and divides them into an easy-to-understand format with timelines, local news and stories presented in a sequence according to the evolution of the facts, for example , the start of a football match, its most important bids, the result and the consequences.
This section which are news that the algorithms think important to you have the name For You, follow 3 more sections so divided: The second section is called Manchete, where the latest news and specific topics are presented. Here is a subsection where you can choose to read the news through Full Coverage by Google, where Google splits it into items from a variety of social media sources, letting you know where and when it happened.
The third section shows favorites, such as the top topics the user usually accesses, the AI has great work there, goes to the owner’s favorite sources, saves stories for later readings, and saves searches according to the location of the texts.
And finally the White Play (White Play) which is the addition of the new Google news, which allows the user to access and subscribe services with premium content in news sites.
While a part of the critique continues to duel with the old canned news schemes linked to editorial groups, the world of personalized news evolves
Alexa: Amazon personal assistant
26
Jun
It may not seem like a new phenomenon in technology since there are wizards like Siri, Cortana or Google Now, but the fact that this wizard is really personal, that’s why I called the others for voice assistants, is the fact that it learns and stores the data in a private cloud from Amazon Web Service (AWS).
or Google Now, but the fact that this wizard is really personal, that’s why I called the others for voice assistants, is the fact that it learns and stores the data in a private cloud from Amazon Web Service (AWS).
These personal assistants although all grounded by the use of voice there are differences, they can learn from specific people habits and functions they desire, while the voice assistant, as I call Siri and Google Now now empordered by Dialogflow, as we explained in the post above, they can respond and learn from human interaction, but may, if it is desirable to organize their own database.
Alexa (because I’m the personal assistant I think is masculine, but it can be the same) is centralized in the Amazon cloud and has its own equipment that is Amazon Echo, a column always connected to the Internet via WiFi that is attentive to dialogues of its “owner”.
Streaming music services using Spotify or Pandora, you can read the news of the main newspapers you prefer, inform the weather forecast or the traffic on the way to work, can control all equipment at home that are Smart Home, including it can identify and tell about compatibility, plus its capacity goes beyond.
In addition, it promises to check basic things like solving math accounts or getting into a conversation and even telling jokes, over time this bank and this ability will evolve.
But beware, we have already written here about the myth of singularity (especially the book by Jean Gabriel Ganascia), the idea that this will turn a monster and control you is less true than to individualize and stop talking to friends and relatives
How do we think it is to think
15
May
From the Algebra of 0 and 1 of Boole, through the first computers of Charles Babbage, arriving  at the thoughts of Vannevar Bush and Norbert Wiener of the MIT of the 40, we came across Alan Turing and Claude Shannon, the final question: the machine one day will think
at the thoughts of Vannevar Bush and Norbert Wiener of the MIT of the 40, we came across Alan Turing and Claude Shannon, the final question: the machine one day will think
What we see between Sophia Robot’s investment appeal to the “personal assistants” market is a long history of what it means to think, but the question now due to technoprofets (name given to the alarmists by Jean-Gabriel Ganascia) is inevitable.
Vannevar Bush had a data processing machine in his MIT lab, where he went to work a trainee named Claude Shannon, says James Gleick who was the one who suggested to his student that he study Boole’s Algebra.
Vannevar Bush in his historical text As We May Think, although it does not say as we would think, speaks of the future possibilities of new advances: “Consider a future device … in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.” (Bush, As We may think).
It creates the embryonic idea of a computer that relates text, as it has done in searches since the beginning of the Gutenberg print, but its Memex machine (picture) was already thought of as a vast capacity of records and communications, even if the phone was still nascent in the final years of World War II and communications depended on powerful antennas.
What is certain is that in the end your text little or almost nothing says about what is actually thinking and as it still is today in Artificial Intelligence, what we have done is to expand more and more the capacity of memory and communication, as well as of large amounts of data, now with techniques called Big Data.
Another contemporary tendency is to ask for the autonomy of the machines, the experiments carried out, even with the so-called “autonomous vehicles” are the basis of algorithms and they depend on the decision making of how the human being will do in certain circumstances, in critical cases, like deciding between two tragedies, the choice can be terrible.
An inimy of the people
01
May
The Brazilian Justice Minister of the STF Edson Fachin quoted Henrik Ibsen (1828-1906) last week, after being defeated against the release of cattle rancher Bumlai and the former treasurer of PP Genu, said he thought about re-reading An enemy of the people, where the Norwegian writer narrates A certain Dr. Stockmann who, being a doctor, claims that the city’s water was contaminated, but that water was the main source of income for that community.
last week, after being defeated against the release of cattle rancher Bumlai and the former treasurer of PP Genu, said he thought about re-reading An enemy of the people, where the Norwegian writer narrates A certain Dr. Stockmann who, being a doctor, claims that the city’s water was contaminated, but that water was the main source of income for that community.
Thus he narrates the contradictions between the conscience of work in favor of the common good and the desire to achieve unanimity, a fact that made Dr. Stockmann come in shock with the petty interests of the city.
Ibsen, whose anarchist ideas had a great influence on intellectuals and politicians of the society of his time, is perhaps one of the reasons that these Nordic countries enjoy a good reputation in relation to corruption, the distribution of income and politicians who do not use politics, but Make it a service.
Anarchist ideals are present when Dr. Stockmann states: ” only free thinking, new ideas, the ability to think differently from the other, the contradictory, can contribute to progress Material and moral of the population, “anarchism aside, is the difficulty for a true dialogue.
She had not read, I read her most famous book is House of Dolls, completed in 1979, and staged for the first time in Copenhagen in Denmark at the theater Det Kongelige Teater, which provoked controversy for denouncing the exclusion of women in modern society, and which gave prominence to Ibsen’s thinking not only in Scandinavia but throughout the world.
What Fachin wanted to point out in citing “An enemy of the people” is the real danger that the Lava-jet operation will probably release all those implicated in the corruption scandals in Brazil, failing to make an important adjustment in our history and we will never be a Sweden or A Norway because there are no leaders capable of pointing out a path of “clean-up” and an end to illicit enrichment from the abuse of the public purse.
On the day of work it would be important not only to make an average with the working class, but to show which polluted waters actually undermine the health of their wages and the public services offered to them.
Significant technologies for Big Data
20
Sep
Big Data is still an emerging technology, the cycle from emergence of a technology until their maturity, if we look at the hypo cycle Gartner curve, we see in it the Big Data on seed from the appearance, to the disappointment, but then comes the maturity cycle.
if we look at the hypo cycle Gartner curve, we see in it the Big Data on seed from the appearance, to the disappointment, but then comes the maturity cycle.
To answer the questions posed in the TechRadar: Big Data, Q1 2017, a new report was produced saying the 22 possible technologies maturities in the next life cycle, including 10 steps to “mature” the Big Data technologies.
In view of this research, the ten points that can, to increase the Big Data are:
- Predictive analytics: software solutions and / or hardware that enable companies to discover, evaluate, optimize and deploy predictive models through the analysis of large data sources to improve business performance and risk mitigation.
- It will take NoSQL databases: key-value, documents and graphic databases.
- Research and knowledge discovery: tools and technologies to support the extraction of information and new perspectives of self-service large data repositories unstructured and structured that reside in multiple sources, such as file systems, databases, streams , APIs and other platforms and applications.
- analysis Flows (analytics Stream): software that can filter, aggregate, enrich and analyze a high data transfer rate from multiple sources online disparate data and any data format (semi-structured).
- Persistent analysis (in-memory) “fabric”: allowing access to low latency and processing large amounts of data by distributing data over the dynamic random access memory (DRAM), Flash or SSD a distributed computer system.
- Distributed stores files: a network of computers where the data are stored in more than one node often replicated way, both redundancy and performance.
- Data virtualization: a technology that provides information from various data sources, including large data sources such as Hadoop tool and distributed data stores in real-time or near-real time (small delays).
This will require the last 3 steps that research suggests: 8. data integration: tools for data orchestration (Amazon Elastic MapReduce (EMR), Apache Hive, Apache Pig, Apache Spark, MapReduce, Couchbase, Hadoop, MongoDB) data preparation (modeling, cleaning and sharing) and data quality (enrichment and data cleansing at high speed) will be needed and that is done, you can make big productive Date “providing values something of growth through a balance Phase “
TDM in Digital Humanities
12
Jul
Digital Humanities is an emerging field that seeks to explore social and 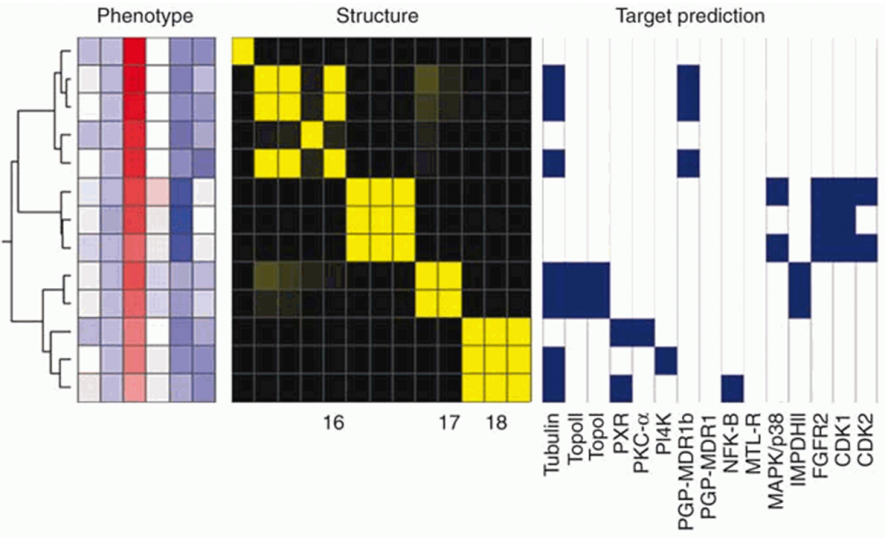 human consequences in digital environments, so consider the more correct name Humanity in Digital Environments, and TDM (Text and Data Mining) is one of these trends.
human consequences in digital environments, so consider the more correct name Humanity in Digital Environments, and TDM (Text and Data Mining) is one of these trends.
A London School blog has just published interesting article that points to a trend that libraries and librarians operate and assist in the use of TDM for research and searches.
The blog explains that in particular the amendment of the Hargreaves review of copyright in the UK, remove legal barriers to explore texts and make data mining (TDM) on the corpus of the research literature, then the article explores how libraries and librarians can facilitate the work of researchers who want to apply TDM methods in library resources to either print or electronic sources.
The article also states that in the case of resource libraries, librarians can advise researchers and encourage them to use the new rules of copyright exceptions, which means that they can overcome certain copyright barriers.
The blog explains that this can mean valuable resources, for example, in research on molecular chemistry (photo), crystallography and other very confidential areas.
The article points out that as an example of Digital Humanities, a major newspaper body of the Victorian era can be mined to extract jokes this time, and can also analyze other aspects of time and UK social history.
It’s not just the electronic corpus that can be extracted, although it article provides a copy of scanning for example TDM purposes to aid the reader.
