


Arquivo para a ‘Bancos de Dados’ Categoria
O platô da pandemia se mantém
06
jul
Os dados observados na última semana de mortes pelo corona vírus, que são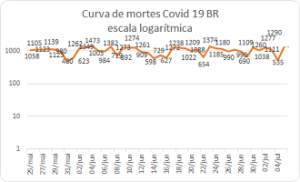 os dados confiáveis, já que a curva de infectados depende da testagem, que é feita por empresas e ainda é baixa, indicam que o platô se mantém e a pandemia se interioriza no Brasil (veja gráfico), já salientamos a importância de fazer o logaritmo para visualizar melhor a inclinação da curva que é exponencial.
os dados confiáveis, já que a curva de infectados depende da testagem, que é feita por empresas e ainda é baixa, indicam que o platô se mantém e a pandemia se interioriza no Brasil (veja gráfico), já salientamos a importância de fazer o logaritmo para visualizar melhor a inclinação da curva que é exponencial.
Qual seria a política para este momento é continuar mantendo o isolamento social, higiene e hábitos de distanciamento social, além das precauções em relação as políticas municipais.
Qualquer perspectiva de um pico, aos menos os dados indicam, parece sem sentido, o número de infecções se mantém em torno de mil mortes diárias, e um #lockdown não é mais viável, pois o vírus já se espalhou e um isolamento regional não significa o controle da pandemia.
Vamos navegar por incertezas, já cansados de um longo período de isolamento e com uma política de abre e fecha que não tem muito resultado efetivo, a não ser o de conter um contágio maior, sem significar qualquer resultado efetivo de controle da pandemia no plano nacional.
Os custos econômicos que seriam grandes no caso de um período de #lockdown, agora serão maiores porque tanto o comércio como os serviços que precisam efetivamente de contato presencial não se justificaria mantê-los desativados, e poucos serviços são não essenciais.
O plano é continuar por prazo indeterminado o chamado “isolamento social”, cujo nome mais certo no caso brasileiro já dissemos, é “distanciamento social” que é compatível com alguns serviços abertos.
O essencial é, portanto, manter os cuidados pessoais e torcer para que a curva caia “naturalmente”.
Quatro buzzwords de TI para 2020
20
jan
Algumas palavras já vem sendo usadas de maneira excessiva e equivocada, pode-se citar tecnologias disruptivas vistas como qualquer uma que tenha impacto no mercado, quando o problema é a escala de produção e consumo, os data lakes, usado para armazenar dados brutos que não significam que são ou podem ser tratados com facilidade (há ambientes e ferramentas específicas para isto), e, o terceiro termo que não é novo também é DevOps que é a rápida implantação de códigos com facilidades de retirar e corrigir possíveis bugs (erros no código).
excessiva e equivocada, pode-se citar tecnologias disruptivas vistas como qualquer uma que tenha impacto no mercado, quando o problema é a escala de produção e consumo, os data lakes, usado para armazenar dados brutos que não significam que são ou podem ser tratados com facilidade (há ambientes e ferramentas específicas para isto), e, o terceiro termo que não é novo também é DevOps que é a rápida implantação de códigos com facilidades de retirar e corrigir possíveis bugs (erros no código).
As quatro buzzwords que devem crescer em 2020 e que representam um perigo tanto no seu uso quanto na implantação são BigData (sim já existia em 2019 mas sua expansão é indicada como um grande volume para 2020), IA idem a anterior, Agile que significa a rapidez de mudança de mercado e de estratégia das empresas, se mal utilizada serão um fracasso e por fim e não menos essencial, e por último, aquilo que resolveu-se chamar de “transformação digital”.
Comecemos pelo último que engloba os anteriores, inclusive os 3 excluídos da análise, transformação digital não significa necessariamente que “tudo agora muda com os processos digitais”, e é claro não significa que nada muda, conforme a área o impacto, a disrupção (no sentido de escala) é claro que o impacto poderá e deverá acontecer, mas cuidado com o Agile.
Agile é o processo de responder rapidamente as mudanças, mas a resposta não significa ser responsivo em qualquer situação, a grande maioria merece análise tais como situações transitórias de mercado, processos sazonais, resposta a concorrência e em especial, mudanças de “moda”.
IA pode ser uma resposta a muitos negócios, mas o próprio termo “inteligência” é questionado, na verdade é um pouco de cada processo anterior, incluindo bigData, Agile e Data lakes, isto é, deve haver ferramentas do tipo Analytics e Machine Learning (foto) que auxiliem o processo.
A Gartner detectou um aumento de 25% para 37% de 2018 para 2019 no uso de IA para negócios, porém a eficácia não é garantida, assim como apenas o uso de TI não significa a modernização da empresa.
Bancos de dados gratuitos
15
fev
Quando mais os bancos de dados open-source crescem, mais as empresas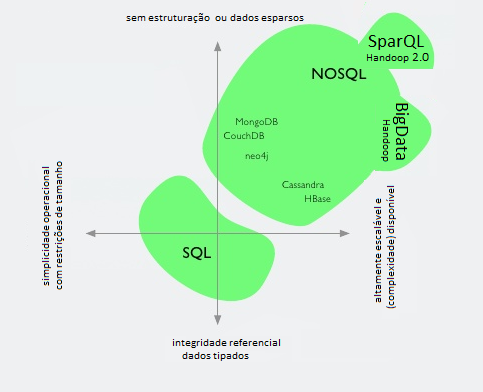 cobiçam este mercado, três concorrente tem ótimos produtos: MySQL, Firebird, PostgreSQL.
cobiçam este mercado, três concorrente tem ótimos produtos: MySQL, Firebird, PostgreSQL.
Alguns obstáculos sempre presentes é ganhar a confiança entre desenvolvedores destes produtos em produtores independentes de software, onde funciona uma falsa ideia que: aquilo que pagamos é o melhor produtos.
Por outro lado desenvolvedores produtos pagos, chamados de software proprietário, é usar as vantagens deste mercado “free” a seu favor, por exemplo, o SQL Server Express, da Microsoft, permite facilidades para migração para sua versão paga, o SQL Server Express, também a geração e um banco de dados em uma Planilha Excel da Microsoft, que é fácil de ser feito pode ser convertida facilmente para o banco Access, que vem junto com seu pacote Windows.
Já o conceito de Bigdata, que exige bancos de dados NoSQL, são aqueles onde uma coleção de bases de dados se tornam tão complexas e volumosas que é muito difícil (em muitos casos impossível) fazer operações simples como remoção, ordenação e sumarização, usando Sistemas Gerenciadores de Bases de Dados tradicionais.
BigData também se referem a dados não estruturados encontrados nas mídias de redes sociais, é uma consequência direta da Web 2.0 que inseriu milhões de usuários como produtores de informação, usam os aplicativos NoSQL (Not only SQL). NoSQL promovendo diversas soluções inovadoras de armazenamento e informações em grande volume.
Essas diversas soluções vêm sendo utilizadas com muita frequência em inúmeras empresas, como por exemplo, IBM, Twitter, Facebook, Google e Yahoo! para o processamento analítico de dados de logs Web, transações convencionais, entre inúmeras outras tarefas.
O SGBD tem um modelo de consistência fortemente baseado no controle transacional ACID (Atomicity, Consistency, Isolation e Durability), mas este modelo é inviável quando estão distribuídos em vários nós, caso típico das redes (importante aqui são redes e não mídias).
O modelo desenvolvido então deve ser outro: CAP (Consistency, Availability e Partition tolerance) onde geralmente somente duas dessas 3 propriedades podem ser garantidas simultaneamente, o que dificulta ainda mais o processamento, mas não se a base de dados for “semiestruturada”, isto é, trabalhar com o princípio que os dados não são estruturados nos formatos convencionais dos bancos SQL.
Dentre os vários produtos NoSQL existentes, podemos considerar que o mais representativo é o Apache Handoop, hoje já existe uma versão adaptada para a Web, chamada Handoop 2.0.
Há outros produtos, entre eles HBase que é um banco de dados distribuídos, orientado a coluna, usa o modelo Google BigTable e é escrito em Java, e outro é o software open-source como Apache Cassandra (originalmente desenvolvido para o Facebook).
HBase é um banco de dados distribuido open-source orientado a coluna, modelado a partir do Google BigTable e escrito em Java.
Há interfaces simples para SQL como arrays associativos ou pares chave-valor (Key-Value pairs), e também padrões para bancos de dados XML nativos com o apoio do padrão XQuery.
Uma linguagem foi desenvolvida para a Web Semântica é o SPARQL (Protocol and RDF Query Language) que tem auxiliado o crescimento de agrupamentos linked data.
Armazenamento 5D eterno
23
fev
É o que promete cientistas da universidade de Southampton, usando uma nanoestrutura ótica do Centro de Pesquisa Optoeletronica (ORC- Optoelectronics Research Centre) usando um armazenamento cinco-dimensional (5D) para escrever dados a laser em femtossegundos (10-15 do segundo ou um milionésimo do nanosegundo), segundo o site da Univ. de Shothampton.
nanoestrutura ótica do Centro de Pesquisa Optoeletronica (ORC- Optoelectronics Research Centre) usando um armazenamento cinco-dimensional (5D) para escrever dados a laser em femtossegundos (10-15 do segundo ou um milionésimo do nanosegundo), segundo o site da Univ. de Shothampton.
O armazenamento prevê propriedades sem precedentes, como estabilidade térmica até temperaturas de 1.000OC, capacidade de 360 TB (tera-bytes) e tempo de vida virtualmente ilimitado cerca de 13,8 bilhões de anos a temperaturas de 190oC.
Um texto já havia sido realizado com armazenamento de 360 kb (Kilo-bytes) gravando uma cópia digital de um texto com sucesso em 5D, agora quatro documentos históricos serão gravados: a Bíblia, a Declaração Universal dos Direitos Humanos (DUDH), a Ótica de Newton, e, a Carta Magna foram guardadas como cópia que poderão sobreviver a raça humana.
Uma cópia do DUDH codificada foi entregue à UNESCO pela ORC, em cerimônia realizada no México, e novos documentos considerados universais poderão ser copiados em 5D.
Google maps off-line disponível
12
nov
Desde terça-feira o Google Maps off-line está disponível no Brasil, a  versão que ficou conhecida assim está disponível para versões para Android a partir da versão 9.17 do Maps, e também para iPhone.
versão que ficou conhecida assim está disponível para versões para Android a partir da versão 9.17 do Maps, e também para iPhone.
O recurso será liberado aos poucos, aparecerá como uma possibilidade de atualização, quando o usuário buscar determinada cidade, aparecerá na tela uma opção para baixá-lo, após a atualização constará do app uma chamada “áreas off-line”.
O recurso foi feito para usuários comuns que querem nomear áreas de passeio, marcar endereços e não tem um plano de dados próprio para isto (por exemplo, empresas que querem aparecer nos maps), no off-line pode ser marcados detalhes de endereços: nomes, localizações, telefones e alguma avaliação por parte dos usuários no caso de empresas.
Tendo uma cópia de dados off-line do mapa, a princípio, mesmo não reduzindo o consumo de dados de um usuário que esteja navegando conectado, ele recebeu este nome justamente porque pode ser usado sem conexão permitindo navegar mais fácil.
O recurso chega em boa hora, porque é comum no mercado brasileiro o corpo da navegação após o limite de dados da franquia, coisa absurda, mas acontece.
Mapeando dados de Big Data
22
set
 Um novo departamento de pesquisa na prestigiosa San Diego State University (SDSU) chamado Centro de Convergência e Informação Estratégica foi fundado, para permitir mapear dados de uma forma parecida que parecida aos dados geográficos, a notícia está no site da SDSU.
Um novo departamento de pesquisa na prestigiosa San Diego State University (SDSU) chamado Centro de Convergência e Informação Estratégica foi fundado, para permitir mapear dados de uma forma parecida que parecida aos dados geográficos, a notícia está no site da SDSU.
O conceito por trás da nova pesquisa é que mapas de números não precisam ser necessariamente geográficos, e não por acaso o centro é um convênio do professor do departamento de Geografia Akshay Pottathil, como um grupo de aficcionados por Tecnologia da Informação.
Estes podem mapear desde ideias ou opiniões até informações de transito, dados estratégicos como população, saúde e outros dados de planejamento urbano.
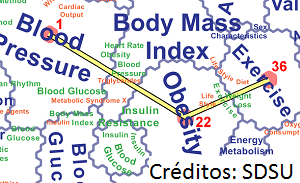
Três conceitos são delineados nestes mapas, a ideia que dados não são estruturados (ou semiestruturados como são chamados no Big Data), visualizar os dados mais rapidamente e o uso estratégico destes dados (foto na saúde, por exemplo).
Pottathil refere-se a estes como “textos não estruturados e outros artefatos de conhecimento”, em linguagem mais simples significa que os dados não estão bem formatados, e veem de uma ampla gama de fontes: artigos de periódicos, artigos de jornais, transcrições de entrevistas, capítulos de livros, blogs, etc e é muito dificil tratá-los nos modos tradicionais de análise de dados para relacionar um do outro.
A segunda questão, afirma Pottathil, está na capacidade de olhar para um desses mapas e muito rapidamente chegar a um entendimento amplo dos temas relacionados com a sua área de interesse, por exemplo, para colaborar em um novo campo, por exemplo, você pode olhar para um mapa idéia para se familiarizar rapidamente com as questões e ver rapidamente um punhado de artigos específicos para este interesse.
Por último, as agências governamentais e grupos de interesse público estão também intrigado com as possibilidades apresentadas por esta tecnologia, já na inauguração do CICS, em agosto, o deputado Scott Peters elogiou a capacidade do centro de utilizar grandes quantidades de dados para lidar com questões sociais.
Snowden fará aparição virtual nos EUA
17
mar
 Nesta segunda-feira começa a feira americana SXSW e Edward Snowden fará uma conversa virtual através do Hangout e poderá dialogar com as pessoas da platéia.
Nesta segunda-feira começa a feira americana SXSW e Edward Snowden fará uma conversa virtual através do Hangout e poderá dialogar com as pessoas da platéia.
Antecipando sua fala ele afirmou que não se arrepende e tudo que fez foi para proteger a maioria dos cidadãos comuns que tiveram sua privacidade “violada em uma escala massiva”.
Como solução para o problema de privacidade, ele afirmou que a comunidade de programação deve desenvolver novos mecanismos para garantir a criptografia e segurança dos dados de comunicação privada.
A SXSW ocorre em Austin (EUA), e a ligação será feita da Rússia, devido a proibição dele entrar nos Estados Unidos por suas denuncias, porém o local onde está localizado continuará em segredo e a transmissão será protegida por sete proxies (ligações com servidores) para despistar qualquer busca de sua localização.
O evento recebeu é chamado de “uma conversa com Edward Snowden” e ele disse que reafirmará que fez “um juramento de apoiar e defender a constituição americana”.
Um problema interessante de Big Data
10
out
Simon DeDeo , um investigação em matemática aplicada e sistemas complexos do Instituto Santa Fé, tinha um problema, conforme postado na revista Wired.
tinha um problema, conforme postado na revista Wired.
Ele estava colaborando em um novo projeto para analisar de dados a partir dos arquivos do tribunal Old Bailey de Londres, um tribunal criminal central da Inglaterra e do País de Gales 300 anos “.
Mas não haviam dados limpos (dizemos estruturados) como em um formato de planilha Excel habitual simples, incluindo variáveis como acusação, julgamento e sentença para cada caso, mas sim cerca de 10 milhões de palavras gravadas durante pouco menos de 200 mil julgamentos.
Como se poderia analisar esses dados ? DeDeo pergunta: “Não é o tamanho do conjunto de dados, que era difícil, por padrões de dados grandes , o tamanho era bastante controlável”. Foi esta enorme complexidade e falta de estrutura formal que representava um problema para estes “grandes dados” que o perturbou.
O paradigma da pesquisa envolveu a formação de uma hipótese, decidir precisamente o que se pretendia medir, em seguida, construir um aparelho para fazer essa medição com a maior precisão possível, não é exatamente como física onde você controla variáveis e tem um número limitado de dados.
Alessandro Vespignani, um físico da Universidade de Northeastern, que é especializada em aproveitar o poder das redes sociais para surtos modelo de doença, o comportamento do mercado de ações, as dinâmicas sociais coletivos, e os resultados eleitorais, coletou muitos terabytes de dados de redes sociais como o Twitter, esta abordagem pode ajudar a tratar textos escritos fora das redes sociais.
Cientistas como DeDeo e Vespignani fazem bom uso dessa abordagem fragmentada para a análise de dados grande, mas o matemático da Yale University, Ronald Coifman diz que o que é realmente necessário é o grande volume de dados equivalente a uma revolução newtoniana, comparando com a invenção do cálculo do século 17, que ele acredita que já está em andamento.
Coifman afirma “Temos todas as peças do quebra-cabeça – agora como é que vamos realmente montá-los”, ou seja, ainda temos que avançar para tratar dados dispersos.
Serviço de nuvem dá anonimato
28
nov
O serviço Amazon de nuvem, apelidado de EC2 (Elastic Compute Cloud) oferece capacidade de serviços virtuais de computador com promessas de confidencialidade por um tipo de estrutura que está sendo chamada de Orion, em projeto open source chamado Tor.
capacidade de serviços virtuais de computador com promessas de confidencialidade por um tipo de estrutura que está sendo chamada de Orion, em projeto open source chamado Tor.
Tor é uma abreviação para The Onion Router, assim chamado devido à natureza multi-camadas da maneira como ele é executado. . É também conhecida como “dar net” (a rede escura).
No blog do projeto, os desenvolvedores afirmaram: “Através da criação de uma ponte, você doar largura de banda para a rede Tor e ajudar a melhorar a segurança e a velocidade com que os usuários podem acessar a internet”, revelando uma nova forma de colaboração que é a uso da banda.
O serviço custa em média normalmente custa £ 19 (perto de R$ 30) por mês, mas a Amazon está oferecendo um ano de armazenamento gratuito como parte de sua promoção, o que significa que o serviço deverá crescer.
O serviço é particularmente elogiado em regimes fechados, em países como Irã e outros do mundo árabe ele tem sido usado e muito elogiado.
Os serviços podem ser acessado no Android através de um aplicativo chamado Orbot e no início desta semana a Apple aprovou Navegador Covert para iPad que passou a ser vendido na App Store, sendo o primeiro aplicativo oficial app iOS que permite aos usuários rotearem suas comunicações on-line através do Tor.
Gerenciamento Eletrônico de Documentos (GED)
29
out
Gerenciadores eletrônicos de documentos (GED em português e ECM, Enterprise Content Management) propiciam que uma empresa, organização ou mesmo uma pessoa gerencie documentos mesmo que não estejam estruturados, ou seja, envolvem estratégias, métodos e ferramentas utilizadas para capturar, gerenciar, armazenar, preservar e distribuir conteúdo e documentos relacionados aos processos de organização do fluxo.
empresa, organização ou mesmo uma pessoa gerencie documentos mesmo que não estejam estruturados, ou seja, envolvem estratégias, métodos e ferramentas utilizadas para capturar, gerenciar, armazenar, preservar e distribuir conteúdo e documentos relacionados aos processos de organização do fluxo.
Neste sentido são mais amplos que os CMS (Content Managment System), como Drupal, Plone, WordPress, etc. que gerenciam conteúdos “carregados” dentro da plataforma e portanto são limitados, pois não é suficiente “gerenciar” o conteúdo.
Duas plataformas mais difundidas de GED são: Alfresco e Knowledge Tree (KT).
As principais motivações para se ter um GED são: o compartilhamento de arquivos é melhorar a colaboração e auditoria em documentos organizacionais. Seis pontos devem ser levados em consideração: métodos para organizar e armazenar de modo simples os documentos, segurança e proteção (isto é crítico, nem sempre levado a sério), capacidade de introduzir metadados, opções de pesquisa (outro ponto crítico), controle de versão e rastreamento de transações e documento de fluxo de trabalho (road map).
As duas ferramentas fazem isto, mas KT é paga, há uma outra paga chamada Dokmee, mais simples mas ao nosso ver mais limitada, mas muitas empresas preferem ferramentas “simples”, para tornar o treinamento simples e garantir o “serviço”.
Tanto Alfresco quanto KT oferecem todas as funcionalidades sugeridas acima, com pequenas diferenças. Os dois têm os conceitos de usuários, grupos e papéis, mas KT fornece ainda a opção de unidades. Todos os usuários tem acesso aos documentos que podem ser controlados em uma escala de simples e com complexas opções de proteção.
Já os metadados e opções globais de pesquisas internas de documentos estão disponíveis em ambos, mas na versão KT estão ativados como padrão enquanto no Alfresco podem ser acrescentados com maior facilidade através de definição de aspectos de herança de acordo com as localidades. E por último ambos têm sistemas de fluxo contínuo de trabalho.
