


Arquivo para fevereiro 15th, 2017
Bancos de dados gratuitos
15
fev
Quando mais os bancos de dados open-source crescem, mais as empresas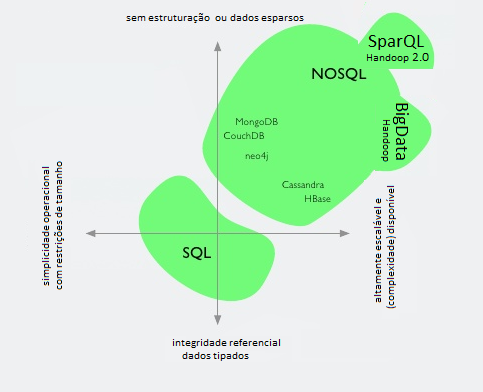 cobiçam este mercado, três concorrente tem ótimos produtos: MySQL, Firebird, PostgreSQL.
cobiçam este mercado, três concorrente tem ótimos produtos: MySQL, Firebird, PostgreSQL.
Alguns obstáculos sempre presentes é ganhar a confiança entre desenvolvedores destes produtos em produtores independentes de software, onde funciona uma falsa ideia que: aquilo que pagamos é o melhor produtos.
Por outro lado desenvolvedores produtos pagos, chamados de software proprietário, é usar as vantagens deste mercado “free” a seu favor, por exemplo, o SQL Server Express, da Microsoft, permite facilidades para migração para sua versão paga, o SQL Server Express, também a geração e um banco de dados em uma Planilha Excel da Microsoft, que é fácil de ser feito pode ser convertida facilmente para o banco Access, que vem junto com seu pacote Windows.
Já o conceito de Bigdata, que exige bancos de dados NoSQL, são aqueles onde uma coleção de bases de dados se tornam tão complexas e volumosas que é muito difícil (em muitos casos impossível) fazer operações simples como remoção, ordenação e sumarização, usando Sistemas Gerenciadores de Bases de Dados tradicionais.
BigData também se referem a dados não estruturados encontrados nas mídias de redes sociais, é uma consequência direta da Web 2.0 que inseriu milhões de usuários como produtores de informação, usam os aplicativos NoSQL (Not only SQL). NoSQL promovendo diversas soluções inovadoras de armazenamento e informações em grande volume.
Essas diversas soluções vêm sendo utilizadas com muita frequência em inúmeras empresas, como por exemplo, IBM, Twitter, Facebook, Google e Yahoo! para o processamento analítico de dados de logs Web, transações convencionais, entre inúmeras outras tarefas.
O SGBD tem um modelo de consistência fortemente baseado no controle transacional ACID (Atomicity, Consistency, Isolation e Durability), mas este modelo é inviável quando estão distribuídos em vários nós, caso típico das redes (importante aqui são redes e não mídias).
O modelo desenvolvido então deve ser outro: CAP (Consistency, Availability e Partition tolerance) onde geralmente somente duas dessas 3 propriedades podem ser garantidas simultaneamente, o que dificulta ainda mais o processamento, mas não se a base de dados for “semiestruturada”, isto é, trabalhar com o princípio que os dados não são estruturados nos formatos convencionais dos bancos SQL.
Dentre os vários produtos NoSQL existentes, podemos considerar que o mais representativo é o Apache Handoop, hoje já existe uma versão adaptada para a Web, chamada Handoop 2.0.
Há outros produtos, entre eles HBase que é um banco de dados distribuídos, orientado a coluna, usa o modelo Google BigTable e é escrito em Java, e outro é o software open-source como Apache Cassandra (originalmente desenvolvido para o Facebook).
HBase é um banco de dados distribuido open-source orientado a coluna, modelado a partir do Google BigTable e escrito em Java.
Há interfaces simples para SQL como arrays associativos ou pares chave-valor (Key-Value pairs), e também padrões para bancos de dados XML nativos com o apoio do padrão XQuery.
Uma linguagem foi desenvolvida para a Web Semântica é o SPARQL (Protocol and RDF Query Language) que tem auxiliado o crescimento de agrupamentos linked data.
