


Arquivo para a ‘Motores de Busca’ Categoria
A Web 4.0 emerge ?
31
out
O impulso inicial de Tim Berners-Lee para criar em meados dos anos 90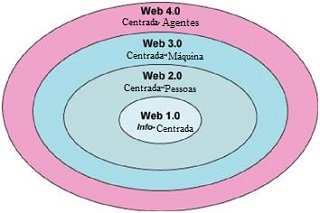 um protocolo sobre a internet, o HTTP (Web e Internet são camadas diferentes) foi para difundir de modo mais rápido a informação científica, podemos dizer então que era uma Web centrada na informação.
um protocolo sobre a internet, o HTTP (Web e Internet são camadas diferentes) foi para difundir de modo mais rápido a informação científica, podemos dizer então que era uma Web centrada na informação.
A Web rapidamente se popularizou, então o crescimento da preocupação com a semântica da Web fez Berners-Lee, James Hendler e Ora Lassila publicaram o paper inaugural Semantic Web: new form of Web content that is meaningful to computers will unleash a revolution of new possibilities, e uma grande parte do desenvolvimento posterior da Web Semântica estava lá projetado como a representação do conhecimento, ontologias, agentes inteligentes e finalmente uma “evolução do conhecimento”.
A Web 2.0 teve como característica inicial a interatividade (O´Reilly, 2005) onde os usuários se tornam mais livres para interagir em páginas da Web e podem marcar, comentar e compartilhar documentos encontrados online.
O artigo apontava o caminho das ontologias, como caminho “natural” para o desenvolvimento e agregar significado a informação na Web Semântica, com metodologias vindo da Inteligência Artificial, que no olhar de James Hendler (Web 3.0) passava por um “inverno” criativo.
Mas três ferramentas integradas acabaram indicando um novo caminho: as ontologias ajudaram a construção de esquemas de organização simples do conhecimento chamado (SKOS – Simple Organization of Knowledge System), um banco de dados para consulta, com uma linguagem chamada SPARQL e aquilo que já era básico na Web Semântica, que era o RDF (Resource DEscription Framework) em sua linguagem descritiva simples: o XML.
O primeiro grande projeto foi o DBpedia, um Banco de Dados proposto pela Free University of Berlin e a University of Leipzig em colaboração com o projeto OpenLink Software, em 2007, que se estruturou em torno do Wikipedia, usando os 3.4 bilhões de conceitos para formar 2.46 de triplas RDF (recurso, propriedade e valor) ou de modo mais simples sujeito-predicado-objeto, indicando uma relação semântica.
Há diversos tipos de Agentes Inteligentes em desenvolvimento, pouco ou quase nada usam a “inteligência” da Web 3.0, haverá no futuro novos desenvolvimentos ? apontamos em artigo recente a ferramenta Semantic Scholar da Fundação Paul Allen, mas ainda a conexão com a Web 3.0 (projetos ligados ao linked data) não é clara.
2016 decididamente ainda não foi o ano da Web Inteligente, ou se quiserem a Web 4.0, mas estamos nos aproximando, os assistentes pessoais (Siri, Cortana, o “M” do Facebook), a domótica (Apple Homekit, Nest), o reconhecimento de imagem e os carros sem motoristas estão logo ali, virando a esquina.
Domótica são os recursos inteligentes caseiros, neste campo a AI cresce rápido.
A internet desaparecerá, diz chefe da Google
27
jan
 Não é o que está pensando, mas sim o fato que ela se tornará de tal forma presente que será impossível se conectar a algo sem utilizá-la, afirmou o chefe da Google Eric Schmidt, na quinta-feira passada em Davos, na Suiça, onde se realizou o Fórum Econômico Mundial.
Não é o que está pensando, mas sim o fato que ela se tornará de tal forma presente que será impossível se conectar a algo sem utilizá-la, afirmou o chefe da Google Eric Schmidt, na quinta-feira passada em Davos, na Suiça, onde se realizou o Fórum Econômico Mundial.
Perguntado sobre o futuro da internet respondeu: “Eu vou responder muito simplesmente que a internet vai desaparecer”, segundo vídeo disponibilizado pela rede de TV norte-americana CNBC.
Mas não quis dizer com isto que a internet pode seguir o caminho dos filmes fotográficos e dos disquetes, mas o entendimento de Schmidt é que a rede será de certa forma tão presente em nosso dia a dia que será inescapável.
Poderá estar presente na vida de uma pessoa do momento que nasce, em todos os momentos da vida de uma pessoa, sua vida familiar, médica, estudantil e atividades sociais diversas, claro com o direito do “esquecimento” que é a possibilidade de desaparecer com registro indesejáveis.
Mas o problema da privacidade permanece, como garantir que dados não sejam extraviados e caiam em mãos que façam mau uso, eis um grande problema a ser resolvido.
FIFA não controlou ingressos
01
jul
Há vários indícios que de alguma forma agências de turismo, espertalhões e cambistas conseguiram ingressos de forma ilegítima (ilegal é questionável já que compraram) mesmo havendo um sorteio, uma desta forma foi furar a fila por um aplicativo de smartphones.
de forma ilegítima (ilegal é questionável já que compraram) mesmo havendo um sorteio, uma desta forma foi furar a fila por um aplicativo de smartphones.
O aplicativo chama-se Scorpyn e existe desde 2011 quando foi criado, no início era uma ferramenta que permitia a digitalização contínua e automática de bilhetagem, verificando a cada 5 segundos, a disponibilidade de ingressos para a Copa.
A rigor isto seria apenas um mecanismo mais rápido do que a tradicional tecla F5 de atualização do site na medida em que os ingressos fossem sendo vendidos, mas o fato apontado por alguns especialistas que o programa dava o número de ingressos disponíveis mostra que de alguma forma ele tinha acesso a toda a base de dados, e portanto poderia controla-la, fazendo compras antecipadas, isto é, furando a fila.
Embora o sistema seja gerenciado por uma empresa americana respeitada, a Akamai Technologies, com sede em Cambridge, Massachusetts, que tem como cliente o NBA da liga americana de basquetes, os indícios de que compras furando a fila foram feitas é claro
Novidades e papelão no Google I/O
27
jun
 O Conferencia Developer Google I/O começou ontem e a empresa fez seu tradicional discurso de abertura dando uma visão geral de todas as notícias reveladoras do evento.
O Conferencia Developer Google I/O começou ontem e a empresa fez seu tradicional discurso de abertura dando uma visão geral de todas as notícias reveladoras do evento.
As mudanças anunciadas além de uma prévia da próxima versão do Android, apelidada de “L” sendo o site TechRunch, foi o desenvolvimento de um novo paradigma de design para sistema operacional do Google que ajuda a trabalhar em diferentes tipos de telas e dispositivos, uma vez que esta fatia de mercado esquentou nos últimos anos: telas flexíveis, diversos tamanhos e resoluções, 3D, etc.
Num discurso de 3 horas, eles falaram de um futuro unificado para o Android e o Chrome no desktop, no celular, até em seu carro e em seu pulso e mais além, e de certa forma não será apenas uma tradução desajeitada e forçada na maneira de usar o software em cada cenário.
Cada ano a Google dá aos participantes da conferência um presente, este ano deu um papelão, mas que papelão !!! era uma caixa que ao rasgar o selo parece um origami que dobrando-o de forma intuitiva torna-se um cheap, um fone de ouvido ou óculos de realidade virtual, bacana !
Google vai as compras de novo
20
mai
A fonte é o The Verge, depois das milionárias compras do YouTube e Motorola Mobile, a próxima poderá ser o gerador de streaming de vídeo Twitch, as cifras giram em torno de 1 bilhão de dólares, mas parece que o assunto ainda está sendo analisado.
a próxima poderá ser o gerador de streaming de vídeo Twitch, as cifras giram em torno de 1 bilhão de dólares, mas parece que o assunto ainda está sendo analisado.
O valor da oferta (que seria de 730 milhões de dólares, está na revista online da “Variety” apesar da gigante de busca já ter o serviço de vídeo YouTube, adquirido em 2006 por 1.6 bilhões de dólares, que é claro, será o serviço diretamente beneficiado ampliando a vantagem no mercado de vídeos.
O Twitch aoareceu em Junho de 2011, feito por Justin Kan e Emmett Shear, o atual presidente executivo da “start-up”, que levantou 35 mil milhões de dólares na época.
Entretanto um dos o negócio pode ser melado pelo departamento de Justiça norte-americano, já que a medida a aquisição do Twitch pode representar uma prática anti-concorrencia, e existem leis de proteção do mercado nos EUA.
.
O YouTube já é o maior “site” de compartilhamento de vídeos na internet, com mil milhões de utilizadores em todo o mundo, mas o Twitch vinha crescendo assim como o Vimeo, o principal concorrente do YouTube.
Realidades e fantasias da Web 3.0
14
nov
Em Novembro de 2006, John Markoff escrevia no New York Times, usando a expressão Web 3.0, dizendo que ela encontraria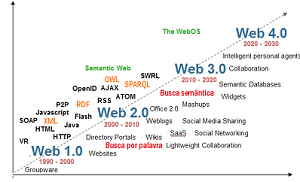 novas formas de mineração de inteligência humana: “A partir dos bilhões de documentos que formam a World Wide Web (rede mundial de computadores) e os links que os ligam, cientistas da computação e um crescente grupo de novas empresas…” (veja a tradução de George El Khouri Andolfato no link bibNews).
novas formas de mineração de inteligência humana: “A partir dos bilhões de documentos que formam a World Wide Web (rede mundial de computadores) e os links que os ligam, cientistas da computação e um crescente grupo de novas empresas…” (veja a tradução de George El Khouri Andolfato no link bibNews).
As definições variam bastantes, desde aqueles que pensam nas características de personalização até a Web Semântica geral e irrestrita, desde fantasias como a de Conrad Wolfram que pensa que a Web 3.0 será o lugar onde “o computador irá gerar novas informações”, até pessimistas como Andrew Keen (O Culto do Amador) que vê na Web 3.0 um retorno aos especialistas e autoridades, chamando-a de “abstração irrealizável”, pela ideia de conectar e organizar informação na Web.
Considero um texto realmente fundador o texto de James Handler, publicado na revista IEEE Computer de janeiro de 2009: “Web 3.0 emerging” on de explica que após inúmeras voltas em torno da Web Semântica, finalmente encontrou tecnologia que podem ajudá-la a realizar-se.
O artigo explica as tecnologias emergentes integradas na Web Semântica já começam a produzir resultados, desde aplicações básicas usando a descrição RDF (no âmbito da descrição de recursos, vincular dados de vários sites da Web usando uma linguagem padrão SQL, a SPARQL que consulta RDF até ligações já prontas em XML ou ontologias em OWL.
Big Data e Bibliotecas
21
ago
A tecnologia de dados do Big Data está pronta para revolucionar todos os aspectos da  vida humana e da cultura como pessoas coletar e analisar grandes volumes de dados para previsão de comportamento, resolução de problemas, segurança e inúmeras outras aplicações, é o que garante o site Christian Science Monitor.
vida humana e da cultura como pessoas coletar e analisar grandes volumes de dados para previsão de comportamento, resolução de problemas, segurança e inúmeras outras aplicações, é o que garante o site Christian Science Monitor.
A geração de grandes quantidades de dados está sendo impulsionada pela crescente digitalização das atividades cotidianas e a dependência das pessoas em dispositivos eletrônicos que deixam “rastros digitais” conceito que pode ser estendido para “rastro da informação”, uma vez que qualquer objeto em qualquer estado de conservação pode conter informação “implícita” que não está ainda num formato adequado.
O site CSMonitor cita um grande projeto de dados notável que é um esforço por os Biblioteca do Congresso dos EUA para arquivar milhões de tweets por dia, cujo benefício pode custar muito pelo seu valor histórico.
Um exemplo, citado é o trabalho de Richard Rothman, professor da Johns Hopkins University, em Baltimore, fundamental: salvar vidas.
Os Centros de Controle e Prevenção de Doenças (CDC) em Atlanta preveem surtos de gripe, e o faz através dos relatórios dos hospitais.
Mas isto levava semanas, em 2009, apareceu um estudo onde pesquisadores puderam prever surtos muito mais rápido através da análise de milhões de buscas na Web, fazia as consultas como “Meu filho está doente” e podiam conhecer um surto de gripe muito antes do CDC soubesse pelos relatórios dos hospitais.
Mas as tecnologias de grandes volumes de dados também tem uma contorno sinistro, em que a tecnologia é percebida potencial de destruir a privacidade, incentivar a desigualdade e promover a vigilância do governo de cidadãos ou outros em nome da segurança nacional, como conciliar estas duas tendências ?
Falha no Google faz internet cair 40%
20
ago
Na última sexta-feira entre os horários das 20h37 e 20h48 (horário de Brasília),  todos os serviços do Google sofreram uma interrupção: Gmail, Drive, Maps, claro o buscador e outros, que segundo nota da empresa durou “entre um e cinco minutos.
todos os serviços do Google sofreram uma interrupção: Gmail, Drive, Maps, claro o buscador e outros, que segundo nota da empresa durou “entre um e cinco minutos.
O Google afirmou em sua página que, durante o período de interrupção, “de 50% a 70% das requisições ao Google receberam mensagens de erro”, mas que o serviço foi corrigido após quatro minutos e foi restaurado para a maioria dos usuários em um minuto.
Segundo a empresa GoSquared houve uma queda de 40% no tráfego de internet mundial naquela noite e o estudou mostrou que, após a queda de poucos minutos, o tráfego de internet disparou logos após a restauração.
Durante a falha, segundo a página do Google, “de 50% a 70% das requisições ao Google receberam mensagens de erro”, mas não informou a origem da falha.
A falha mostrou o quanto a internet ainda é frágil e as possibilidades de danos mesmo que temporários não é uma falácia.
Altavista buscador pioneiro será desativado
03
jul
Na próxima segunda-feira (08/07) o buscador pioneiro  Altavista, com 18 anos de existência será desativado, ele possui página no Brasil e já foi muito popular no país.
Altavista, com 18 anos de existência será desativado, ele possui página no Brasil e já foi muito popular no país.
Eram populares nos anos 90 também o Lycos, Infoseek e Yahoo.
Foi criado quando a Web nascia e a Internet já tinha vinte nos, em 1995, mas mudou de donos várias vezes, criador pela Digital (DEC, Digital Equipment Corporation) foi comprado pela Compaq em 1998 e quando esta foi comprada pela HP trocou de mãos.
A HP vendeu o vovô buscador para a Oberture, que no mesmo ano foi comprada pela Yahoo, em 2003.
Com isto o império do gigante de busca fica mais forte, porém não faltam críticas quanto a semântica, relevância e volume das buscas do Google.
O risco científico e o "Big Data"
09
abr
As grandes pesquisas em computação estão se voltando para grandes volumes de dados, o chamado Big Data, conforme notícia do New York Times.
voltando para grandes volumes de dados, o chamado Big Data, conforme notícia do New York Times.
A Universidade de Columbia, para “debutar” seu novo Instituto de Ciências e Engenharia de Dados, realizou na última sexta-feira (05/04) um simpósio de um dia inteiro intitulado “Do Big Data às Big Ideias”.
O instituto é uma junção de centros interdisciplinares, para a segurança cibernética, análises financeiras, análises de saúde, novas mídias e cidades inteligentes.
Diversas análises sobre conjunto de tecnologias chamado Big Data, com novos dados e novas ferramentas de inteligência artificial, que poderão realmente transformar as indústrias, como novas capacidades de previsão.
O simpósio, “Do Big Data Para Big Ideas”, foi, principalmente, uma celebração da promessa da tecnologia nos campos de cuidados de saúde ao transporte, com apresentações de Columbia professores e cientistas da computação de empresas como Google, Facebook, Microsoft e Bloomberg.
Os perigos de privacidade e vigilância de Big Data também surgiram de passagem, mas durante uma seção de perguntas e respostas de um painel, o oficial de informações da Google, Ben Fried, expressou um receio. “Minha preocupação é que a tecnologia está muito à frente da sociedade”, disse Fried disse. “Há perigo”, ele sugeriu, “que apenas uma elite técnica entender Big Data e suas implicações, com o risco de uma tecnologia de fuga ou uma rejeição do público”.
