


Arquivo para a ‘Mineração de dados’ Categoria
O platô da pandemia se mantém
06
jul
Os dados observados na última semana de mortes pelo corona vírus, que são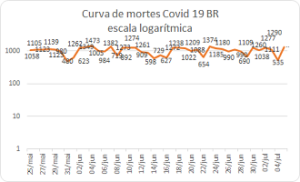 os dados confiáveis, já que a curva de infectados depende da testagem, que é feita por empresas e ainda é baixa, indicam que o platô se mantém e a pandemia se interioriza no Brasil (veja gráfico), já salientamos a importância de fazer o logaritmo para visualizar melhor a inclinação da curva que é exponencial.
os dados confiáveis, já que a curva de infectados depende da testagem, que é feita por empresas e ainda é baixa, indicam que o platô se mantém e a pandemia se interioriza no Brasil (veja gráfico), já salientamos a importância de fazer o logaritmo para visualizar melhor a inclinação da curva que é exponencial.
Qual seria a política para este momento é continuar mantendo o isolamento social, higiene e hábitos de distanciamento social, além das precauções em relação as políticas municipais.
Qualquer perspectiva de um pico, aos menos os dados indicam, parece sem sentido, o número de infecções se mantém em torno de mil mortes diárias, e um #lockdown não é mais viável, pois o vírus já se espalhou e um isolamento regional não significa o controle da pandemia.
Vamos navegar por incertezas, já cansados de um longo período de isolamento e com uma política de abre e fecha que não tem muito resultado efetivo, a não ser o de conter um contágio maior, sem significar qualquer resultado efetivo de controle da pandemia no plano nacional.
Os custos econômicos que seriam grandes no caso de um período de #lockdown, agora serão maiores porque tanto o comércio como os serviços que precisam efetivamente de contato presencial não se justificaria mantê-los desativados, e poucos serviços são não essenciais.
O plano é continuar por prazo indeterminado o chamado “isolamento social”, cujo nome mais certo no caso brasileiro já dissemos, é “distanciamento social” que é compatível com alguns serviços abertos.
O essencial é, portanto, manter os cuidados pessoais e torcer para que a curva caia “naturalmente”.
Rumo a computação sem servidor
27
jan
Entre as tendências apontadas pela Nasdaq,  a bolsa de valores dos eletrônicos, está a chamada computação sem servidor, com a transferência das funções para o armazenamento em nuvens.
a bolsa de valores dos eletrônicos, está a chamada computação sem servidor, com a transferência das funções para o armazenamento em nuvens.
As nuvens passam a gerenciar as funções e o armazenamento feito pelos servidores, a computação fica mais ágil e menos dependente dos dispositivos móveis, que também começam a migrar para a IoT (Internet das Coisas) e assim a tendência geral poderá ser uma transformação digital, não a buzzword da moda, mas na própria estrutura do universo digital.
Outra consequência será a transferência e simplificação e muitas funções para a Web, que é confundida com a internet, mas é apenas uma fina camada sobre ela, escrita através de um interpretador (uma linguagem de computação com alta interatividade) que é o HTTP.
A criação e execução de aplicativos fica assim mais simples, mas isto não é propriamente a computação sem servidor como indica uma literatura superficial da área, e sim uma das importantes consequências dela.
A tecnologia de Função como um Serviço (Function as a Service) é diferente das definições de aplicações me Nuvens (IaaS, Infraestrutura como serviço e PaaS, Plataforma como serviço), onde os códigos são escritos sem que seja preciso saber em que servidor aquela aplicação vai ser executada.
Estamos chegando perto, mas do que ?
17
set
Aos 20 anos, o romance de Carl Sagan “Contato” (1985) me impressionou de tal modo que nunca mais saiu da minha imaginação, o livro

Contato, Buraco de Minhoca e radioastronomia.
falava de buracos de minhoca (wormholes são caminhos possíveis para a quarta dimensão), de teologia e de busca de vidas em outros planetas, eu fazia um caminho em direção ao materialismo que durou 20 anos, mas foi um percurso intelectual.
Aos 42 anos, o filme Contato (1987) voltou a me impressionar, a protagonista a Ellie Arroway (Jody Foster), na ficção era do SETI (Search for Extraterrestrial Intelligence), descubro agora que o departamento existe na Universidade de Berkeley e lá estão captando sinais vindos de uma estrela vindos de uma estrela distante.
Curioso e instigante, é justamente a fase em que retorno a estudar a Noosfera de Teilhard de Chardin e pesquisar a quarta dimensão, estamos preparando um holograma e uma Ode ao Christus Hypercubus em Lisboa, justamente uma referência de Salvador Dali a 4ª. dimensão.
Os pesquisadores do SETI de Berkeley, liderados pelo estudante Gerry Zhang e alguns colaboradores, usaram aprendizado de máquina (machine learning) para construir um algoritmo novo para sinais de rádio que identificaram num período de 5 horas em 26 de agosto de 2017 (puxa meu aniversario), mas deve ser só uma coincidência.
Zhang e seus colegas com o novo algoritmo resolveram reanalisar os dados de 2017 e encontraram 72 explosões adicionais, os sinais não parecem comunicações como conhecemos, mas verdadeiras explosões, e Zhang e seus colegas preveem um novo futuro para a análise de sinais de radioastronomia com uso de aprendizagem de máquina.
Como no filme o sinal precisou de muito tempo para ser decodificado, Turing que estudou a máquina Enigma capturada do exército alemão durante a Segunda Guerra, adoraria estudar isto hoje, ele a decifrou.
O universo de código não é, portanto, artefacto humano, o espaço está cheio dele, não quer dizer que seja de alguma civilização, mas eles estão lá, a radiação de fundo por exemplo, descoberta em 1978 por Penzias e Wilson, ratificou o Big Bang e deu-lhes um Nobel de Física.
Os novos resultados serão publicados este mês no The Astrophycal Journal, e está disponível no site Breaktrough Listen.
Questões simples e complexas da Web Semântica
05
jul
Sempre nos deparamos com conceitos alguma parecem uma coisa no senso comum e não o são,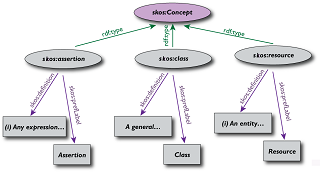 tornam-se complexas coisas que eram simples, é o caso de muitos exemplos: as redes sociais (confundidas com as Mídias), os fractais (números ainda genéricos demais para serem usados no dia a dia, mas importantes), a inteligência artificial (que não é a humana), enfim inúmeros casos, podendo ir para o virtual (não é o irreal), as ontologias, etc.
tornam-se complexas coisas que eram simples, é o caso de muitos exemplos: as redes sociais (confundidas com as Mídias), os fractais (números ainda genéricos demais para serem usados no dia a dia, mas importantes), a inteligência artificial (que não é a humana), enfim inúmeros casos, podendo ir para o virtual (não é o irreal), as ontologias, etc.
Estes são os casos da Web Semântica e das Ontologias, onde toda simplificação leva a um erro.
Provavelmente por isso, um dos precursores da Web Semântica Tim Hendler, escreveu um livro Semantic Web for Ontologists modelling: : Effective Modelling in RDFS and OWL (Allemang, Hendler, 2008).
Os autores explicam no capítulo 3 que quando se fala de Web Semântica “de uma linguagem de programação, normalmente nos referimos ao mapeamento da sintaxe da linguagem para algum formalismo que expressa o “significado” dessa linguagem.
Agora quando falamos “de semântica´ da linguagem natural, muitas vezes nos referimos a algo sobre o que significa entender o enunciado – como ir das letras ou sons estruturados de uma linguagem para algum tipo de significado por trás deles. Talvez a parte mais primitiva dessa noção de semântica seja uma representação da ligação de um termo em uma declaração à entidade no mundo a que o termo se refere.” (Allemang, Hendler, 2008).
Quando falamos de coisas do mundo, no caso da Web Semântica falamos de Recursos, conforme dizem os autores talvez isto seja a coisa mais incomum para a palavra recurso, e para elas foi criada uma linguagem de definição chamada RDF como Framework de Descrição dos Recursos, e eles na Web tem uma unidade de identificação básica chamada URI, juntamente um Identificador Uniforme de Recursos.
No livro os autores desenvolvem uma forma avançada de RDF chamada de RDF Plus, que já tem muitos usuários e desenvolvedores, para modelar também ontologias usando uma linguagem própria para elas que é o OWL, o primeiro aplicativo é chamado SKOS, Uma Organização simples do Conhecimento, que propõe a organização de conceitos como dicionários de sinônimos, taxonomias e vocabulários controlados em RDF.
Como o RDF-Plus é um sistema de modelagem que fornece suporte considerável para informações distribuídas e federação de informações, é um modelo que introduz o uso de ontologias na Web Semântica de modo claro e rigoroso, embora complexo.
Allemang, D. Hendler, J. Semantic Web for the Working Ontologist: Effective Modelling in RDFS and OWL, Morgan Kaufmann Publishing, 2008.
Tendências da Inteligência artificial
10
mai
No final dos anos 80 as promessas e desafios da Inteligência artificial pareciam desmoronar a frase de Hans Moracev: “é fácil fazer os computado- res exibirem desempenho de nível adulto em testes de inteligência ou jogar damas, e é difícil ou impossível dar a eles as habilidades de um garoto de um ano quando se trata de percepção e mobilidade”, em seu livro de 1988 “Mind Children”.
de Hans Moracev: “é fácil fazer os computado- res exibirem desempenho de nível adulto em testes de inteligência ou jogar damas, e é difícil ou impossível dar a eles as habilidades de um garoto de um ano quando se trata de percepção e mobilidade”, em seu livro de 1988 “Mind Children”.
Também um dos maiores precursores da IA (Inteligência Artificial) Marvin Minsky e co-fundador do Laboratório de Inteligência Artificial, declarava no final dos anos 90: “A história da IA é engraçada, pois os primeiros feitos reais eram belas coisas, máquina que fazia demonstrações em lógica e saía-se bem no curso de cálculo. Mas, depois, a tentar fazer máquinas capazes de responder perguntas sobre históricas simples, máquina … 1º. ano do cicio básico. Hoje não há nenhuma máquina que consiga isto.” (KAKU, 2001, p. 131)
Minsky junto com outro precursor de IA: Seymor Papert, chegou a vislumbrar uma teoria d’A Sociedade da Mente, que buscava explicar como o que chamamos de inteligência poderia ser um produto da interação de partes não-inteligentes, mas o caminho da IA seria outro, ambos faleceram no ano de 2016 vendo a virada da IA, sem ver a “sociedade da mente” emergir.
Graças a uma demanda da nascente Web cujos dados careciam de “significado”, os trabalhos de IA vão se unir aos esforços dos projetistas da Web para desenvolver a chamada Web Semântica.
Já havia dispositivos os softbots, ou simplesmente bots, robôs de software que navegavam pelos dados brutos procurando “capturar alguma informação”, na prática eram scripts escritos para Web ou para a Internet, que poderiam agora ter uma função mais nobre do que roubar dados.
Renasceu assim a ideia de agentes inteligentes, vinda de fragmentos de código, ela passa a ter na Web uma função diferente, a de rastrear dados semiestruturados, armazená-los em bancos de dados diferenciados, que não são mais SQL (Structured Query Language), mas procurar questões dentro das perguntas e respostas que são feitas na Web, então estes bancos são chamados de No-SQL, e eles servirão de base também para o Big-Data.
O desafio emergente agora é construir taxonomias e ontologias com estas informações dispersas na Web, semi-estruturadas, que nem sempre estão respondendo a um questionário bem formulado ou a raciocínios lógicos dentro de uma construção formal clara.
Neste contexto emergiu o linked data, a ideia de ligar dados dos recursos na Web, investigando-os dentro das URI (Uniform Resource Identifier) que são os registros e localização de dados na Web.
O cenário perturbador no final dos anos 90 teve uma virada semântica nos anos 2000.
KAKU, M. A física do Impossível: uma exploração científica do mundo dos fasers, campos de forças, teletransporte e viagens do tempo. 1ª. Edição. Lisboa: Editorial Bizâncio, 2008.
AI pode detectar discurso de ódio
17
out
É crescente nas mídias sociais o discurso de ódio, identifica-lo com uma única fonte  pode ser perigoso e tendencioso, em função disto pesquisadores da Finlândia treinaram um algoritmo de aprendizagem para identificar o discurso do ódio comparando-o computacionalmente com o que diferencia o texto que inclui o discurso em um sistema de categorização como “de ódio”.
pode ser perigoso e tendencioso, em função disto pesquisadores da Finlândia treinaram um algoritmo de aprendizagem para identificar o discurso do ódio comparando-o computacionalmente com o que diferencia o texto que inclui o discurso em um sistema de categorização como “de ódio”.
Os pesquisadores empregaram o algoritmo diariamente para visualizar todo o conteúdo aberto que os candidatos em eleições municipais geraram tanto no Facebook como no Twitter.
O algoritmo foi ensinado usando milhares de mensagem, que foram analisadas de forma cruzada para confirmar a validade científica, segundo Salla-Maaria Laaksonen, da Universidade de Helsinque: “Ao categorizar as mensagens, o pesquisador deve tomar uma posição sobre a linguagem e o contexto e, portanto, é importante que várias pessoas participem na interpretação do material didático”, por exemplo, fazer um discurso odioso para defender-se de uma ação odiosa.
O algoritmo foi ensinado usando milhares de mensagens, que foram analisadas de forma cruzada para confirmar a validade científica, explica Salla-Maaria:“When categorizing messages, the researcher has to take a stance on the language and context, and it is therefore important that several people participate in interpreting the teaching material,” says the University of Helsinki’s Salla-Maaria Laaksonen. “ao categorizar as mensagens, o pesquisador deve tomar uma posição sobre a linguagem e o contexto e, portanto, é importante que várias pessoas participem na interpretação do material didático”, senão o ódio pode ser identificado apenas unilateralmente. She says social media services and platforms could identify hate speech if they wanted to, and in that way influence the activities of Internet users.
Ela diz que os serviços e plataformas de mídia social podem identificar o discurso de ódio se quiserem, e dessa forma influenciam as atividades dos usuários da Internet. “There is no other way to extend it to the level of individual citizens,” Laaksonen notes. “não há outra maneira de estendê-lo ao nível dos cidadãos individuais”, observa Laaksonen, ou seja, são semi automáticos porque preveem a interação humana na categorização.
O artigo completo pode ser lido no site da Aalto University de Helsinque.
A Web 4.0 emerge ?
31
out
O impulso inicial de Tim Berners-Lee para criar em meados dos anos 90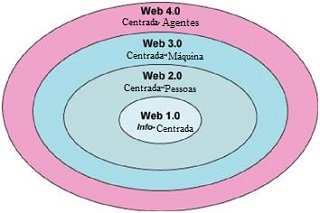 um protocolo sobre a internet, o HTTP (Web e Internet são camadas diferentes) foi para difundir de modo mais rápido a informação científica, podemos dizer então que era uma Web centrada na informação.
um protocolo sobre a internet, o HTTP (Web e Internet são camadas diferentes) foi para difundir de modo mais rápido a informação científica, podemos dizer então que era uma Web centrada na informação.
A Web rapidamente se popularizou, então o crescimento da preocupação com a semântica da Web fez Berners-Lee, James Hendler e Ora Lassila publicaram o paper inaugural Semantic Web: new form of Web content that is meaningful to computers will unleash a revolution of new possibilities, e uma grande parte do desenvolvimento posterior da Web Semântica estava lá projetado como a representação do conhecimento, ontologias, agentes inteligentes e finalmente uma “evolução do conhecimento”.
A Web 2.0 teve como característica inicial a interatividade (O´Reilly, 2005) onde os usuários se tornam mais livres para interagir em páginas da Web e podem marcar, comentar e compartilhar documentos encontrados online.
O artigo apontava o caminho das ontologias, como caminho “natural” para o desenvolvimento e agregar significado a informação na Web Semântica, com metodologias vindo da Inteligência Artificial, que no olhar de James Hendler (Web 3.0) passava por um “inverno” criativo.
Mas três ferramentas integradas acabaram indicando um novo caminho: as ontologias ajudaram a construção de esquemas de organização simples do conhecimento chamado (SKOS – Simple Organization of Knowledge System), um banco de dados para consulta, com uma linguagem chamada SPARQL e aquilo que já era básico na Web Semântica, que era o RDF (Resource DEscription Framework) em sua linguagem descritiva simples: o XML.
O primeiro grande projeto foi o DBpedia, um Banco de Dados proposto pela Free University of Berlin e a University of Leipzig em colaboração com o projeto OpenLink Software, em 2007, que se estruturou em torno do Wikipedia, usando os 3.4 bilhões de conceitos para formar 2.46 de triplas RDF (recurso, propriedade e valor) ou de modo mais simples sujeito-predicado-objeto, indicando uma relação semântica.
Há diversos tipos de Agentes Inteligentes em desenvolvimento, pouco ou quase nada usam a “inteligência” da Web 3.0, haverá no futuro novos desenvolvimentos ? apontamos em artigo recente a ferramenta Semantic Scholar da Fundação Paul Allen, mas ainda a conexão com a Web 3.0 (projetos ligados ao linked data) não é clara.
2016 decididamente ainda não foi o ano da Web Inteligente, ou se quiserem a Web 4.0, mas estamos nos aproximando, os assistentes pessoais (Siri, Cortana, o “M” do Facebook), a domótica (Apple Homekit, Nest), o reconhecimento de imagem e os carros sem motoristas estão logo ali, virando a esquina.
Domótica são os recursos inteligentes caseiros, neste campo a AI cresce rápido.
Scholar Semantic é uma novidade ?
26
out
A Google poderá perder terreno, desde novembro está online uma versão BETA do Scholar Semantic, que faz busca semântica na Web através de artigos envolvendo autores e suas referências.
do Scholar Semantic, que faz busca semântica na Web através de artigos envolvendo autores e suas referências.
Quando se trata de literatura científica faz algumas décadas que vivemos uma sobrecarga de artigos científicos, áreas como a Ciência da Informação já estudam este fenômeno a anos, mas agora a Google parece querem abalar os alicerces das “buscas” no ambiente da Web.
Mas o número agora é astronômico, mais de 100 milhões de papers acadêmicos estão online, e o crescimento é de cerca de 5.00 artigos por dia, como tratar este volume de dados.
O Instituto Allen, dedicado a Paul Allen promete balançar este “mercado” com o lançamento da ferramenta já disponível Scholar Semantic, fiz uma busca no meu nome e já achei alguma coisa.
Lançado em novembro de 2015, e ainda com uma versão beta, o buscador online procura abranger a área de informática, limitada ainda a cerca de 3 milhões de artigos, portanto 3% do universo atual, mas a área de Neurociência já está disponível em 2016, e outras áreas médicas começaram a aparecer.
Oren Etzioni, o chefe do projeto de Inteligência Artificial intitulado de EA2, disse em entrevista que é “impossível não se incomodar com tudo que estamos descobrindo estes dias”.
Deverão avançar mais agora na área médica, porque ela é “tão visceral”, disse Etzioni, e comparando com os serviços de Google Scholar ou PubMed, a capacidade de destacar os papers mais importantes e suas ligações com outros papers, poderão direcionar as pesquisas num futuro muito próximo.
Em quanto tempo este futuro chegará até nós ? Etzione responde: “Eu acho que os primeiros serviços de “assistentes científicos” vão surgir nos próximos 10 anos e eles estão poderão ficar melhores a cada dia, “Nós não estamos falando muito além do horizonte, veremos isto em muito breve”.
Pode já acessar o programa EA2 Semantic Scholar ou pelo site semanticscholar.org , já há vermos também para iOs e Android.
Tecnologias significativas para Big Data
20
set
Big Data ainda é uma tecnologia emergente, no ciclo que vai do surgimento de uma tecnologia até a sua maturidade, se olharmos o hipociclo da curva de Gartner, veremos nela o Big Data na descendência desde o surgimento, até a desilusão, mas depois vem o ciclo da maturidade.
sua maturidade, se olharmos o hipociclo da curva de Gartner, veremos nela o Big Data na descendência desde o surgimento, até a desilusão, mas depois vem o ciclo da maturidade.
Para responder a questões propostas na TechRadar: Big Data, Q1 2017, um novo relatório foi produzido dizendo da 22 tecnologias de possíveis maturidades nos próximos ciclo de vida, entre as quais, 10 passos para “amadurecer” as tecnologias Big Data.
Na opinião desta pesquisa, os dez pontos que poderão, para incrementar o Big Data, são:
- A análise preditiva: soluções de software e / ou hardware que permitem que as empresas descobrem, avaliem, otimizem e implantem modelos preditivos através da análise de fontes de dados grandes para melhorar o desempenho dos negócios ou mitigação de risco.
- Serão necessários bancos de dados NoSQL: key-value, documentos e bases de dados gráfica.
- Pesquisa e descoberta de conhecimento: ferramentas e tecnologias para apoiar a extração de informações e novas perspectivas de auto-atendimento de grandes repositórios de dados não estruturados e estruturados que residem em múltiplas fontes, tais como sistemas de arquivos, bancos de dados, córregos, APIs e outras plataformas e aplicações.
- Fluxos de análises (analytics Stream): software que podem filtrar, agregar, enriquecer e analisar uma alta taxa de transferência de dados de múltiplas fontes de dados on-line díspares e em qualquer formato de dados (semi-estruturados).
- Análise persistente (In-memory) de “tecidos” de dados: permite o acesso de baixa latência e processamento de grandes quantidades de dados através da distribuição de dados através da memória de acesso aleatório dinâmico (DRAM), Flash, ou SSD de um sistema de computador distribuído.
- Arquivos de lojas Distribuídas: uma rede de computadores onde os dados são armazenados em mais de um nó, muitas vezes de forma replicada, tanto a redundância como desempenho.
- A virtualização de dados: uma tecnologia que fornece informações de várias fontes de dados, incluindo fontes grandes de dados, como a ferramenta Hadoop e armazenamentos de dados distribuídos em tempo real e ou tempo quase-real (pequenos delays).
Isto vai exigir as 3 ultimas etapas que a pesquisa sugere: 8. integração de dados: ferramentas para a orquestração de dados (Amazon Elastic MapReduce (EMR), Apache Hive, Apache Pig, Apache Spark, MapReduce, Couchbase, Hadoop, MongoDB), preparação de dados (modelagem, limpeza e compartilhamento) e a qualidade dos dados (enriquecimento e limpeza de dados em alta velocidade) serão necessários e feito isto, poderá tornar o Big Data produtivo “fornecendo valores de algo de crescimento através de uma Fase de Equilíbrio”.
Auxiliando a transparência na Web
19
out
Uma ferramenta de segunda geração, chamada Sunlight está sendo desenvolvida para possibilitar maior transparência no uso de dados pessoais na Web.
para possibilitar maior transparência no uso de dados pessoais na Web.
Como a navegação na Web é cada dia mais fácil, e a cada dia o monitoramento corporativo de nossos e-mails e hábitos são mais e mais explorados, a ferramenta desenvolvida no departamento de Engenharia da Universidade de Columbia, EUA, serve para evitar e avisar como e quando os nossos dados estão sendo usados.
Segundo Roxana Geambasu, cientista da Columbia e do Instituto de Ciência dos Dados, “A Web é como o Velho Oeste”, onde “não há nenhuma supervisão de como nossos dados estão sendo recolhidos, trocados e usados”, e caindo em mãos erradas podem ser usados contra nós.
Segundo Daniel Hsu, outro pesquisador do grupo, a ferramenta é a primeira a analisar numerosas entradas e saídas em conjunto para formar hipóteses que são testadas em um conjunto de dados separado selecionados a partir dos originais.
No final, cada hipótese, e sua entrada e saída ligada, está classificado para a confiança estatística e segundo Hsu “Estamos tentando encontrar um equilíbrio entre confiança estatística e escala para que possamos começar a ver o que está acontecendo em toda a Web como um todo”.
Os pesquisadores montaram os textos a partir de 119 contas de Gmail, e por mais de um mês no ano passado, enviaram 300 mensagens com palavras sensíveis na linha de assunto e no corpo de email, e encontraram, por exemplo, cruzando palavras “desempregados”, “judeu” e “deprimido” foram usadas parar acionar anúncios para “auto financiamento fácil”.
A ferramenta é claro, não resolve estes problemas, apenas denuncia a existência destes casos.
